应用企业搜索的市场巨变——ChatGPT撬动百亿级应用搜索的AIGC市场
我们刚刚经历的不可思议的一周。本周,再次迎来了Open AI的另一个王炸。

我们先来看一下简单的新闻稿:
北美时间3月23日,Open AI在官网宣布推出ChatGPT插件功能,同时开源知识库检索插件源代码! (插件申请地址:https://openai.com/waitlist/plugins) 据悉,该插件使ChatGPT 能够连接到第三方应用程序并与开发人员定义的 API 进行交互,从而增强 ChatGPT 的功能并允许执行更广泛的操作,例如,查询股票价格、查询公司文件、执行订机票等。这是全球企业、个人开发者万众期待的功能!自Open AI推出ChatGPT以来,用户便一直要求上线该功能。现在,它终于向我们走来了,这标志着一个真正的智能交互应用时代降临!
正如描述,这个工具将标志着一个真正的智能交互应用时代降临!我们在应用领域的搜索体验,将由以前的基于分词的全文检索、基于向量的语义搜索来返回结果页的时代,全面进入一个由AI生成结果,并进行交互式查询的时代。
在不远的将来,我们可能将会看到,互联网和移动互联网上,现在无数的网站、应用上提供的搜索框将变成一个智能对话框。而在这之下,底层的软硬件基础设施将会出现巨大的迭代升级,AI将无处不在。
ChatGPT对用户搜索体验的颠覆
为了便于理解,我们先简单回顾一下对于ChatGPT之于搜索的意义。在过去的2个月当中,我们一直是把它当成了对通用搜索引擎比如google,baidu的颠覆。其颠覆性的能力表现为:
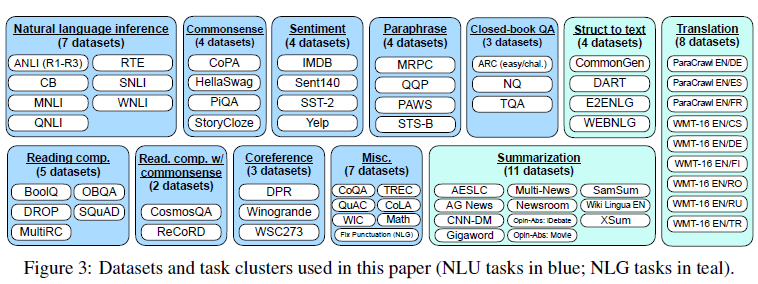
自然语言理解:ChatGPT能够理解用户的问题并生成类似人类的回答。这使得用户可以使用自然语言与系统进行交互,而无需使用特定的关键词或查询语句。
上下文感知:ChatGPT可以理解并考虑用户提供的上下文信息,从而生成更加相关和有针对性的回答。传统搜索引擎通常仅基于关键词进行检索,而不是理解整个对话的含义。
个性化和交互性:ChatGPT可以根据用户的喜好和需求生成个性化的回答,同时允许用户在对话中提出问题、提供反馈或者要求澄清。与传统搜索引擎相比,这提供了更高程度的交互性和用户体验。
我们看到用户也快速适应和接受了这样一种用户体验,chatGPT成了日活用户增长最快的爆品。所有的自媒体都在火热宣传chatGPT和AIGC。厂商,资本,对AIGC趋之若鹜。各个科技大厂,纷纷跟进。
ChatGPT插件赋能应用搜索
但在彼时,chatGPT还是一个直接的2C场景的应用。对于企业用户、在应用内搜索和企业搜索引擎领域,我们无法集成这种能力的。而这个Open AI的新王炸chatgpt-retrieval-plugin,则解决了这个问题。
我们先来看一下chatGPT本身是如何解读这个插件带来的颠覆性功能的:

也就是说,它首先能够使用优秀的理解能力,将用户的查询转化为向量语义,通过向量搜索获取结果后,再将其以生成内容的方式呈现给客户,同时能够带入chatGPT的优秀用户体验比如已经对话式的任务。
那么,它是怎么给企业的数据连接的呢?
我们可以把企业内部的数据通过OpenAI提供的向量模型(text-embedding-ada-002),转化为向量存储在企业自己的向量搜索引擎当中时。在检索时,以向量相似性搜索,将用户的查询和向量库中的数据进行相似性匹配,获得结果后,再通过该插件,把结果交给chatGPT生成。
用户获得的是chatGPT插件提供的用户体验,而企业自有的数据库则在背后为chatGPT插件提供自有知识来源来生成更准确、更有洞察力的回答。
这样,我们就可以在保持数据私有化的同时,结合chatGPT的内容生成和对话式任务的能力,把新一代的搜索体验赋能给我们的企业搜索。

应用搜索、企业搜索架构巨变
对于要接入chatGPT能力,或者说将来打算通过其他大模型平台提供交互式语义搜搜能力的企业来说,巨变将来自于现有的软硬件基础设施的迭代升级。
首先,企业需要能将数据转化为embedding(向量)
然后,有能存储embedding并进行向量相似性搜索能力的数据库
应用上搜索的接口将与chatGPT retrival plugin整合
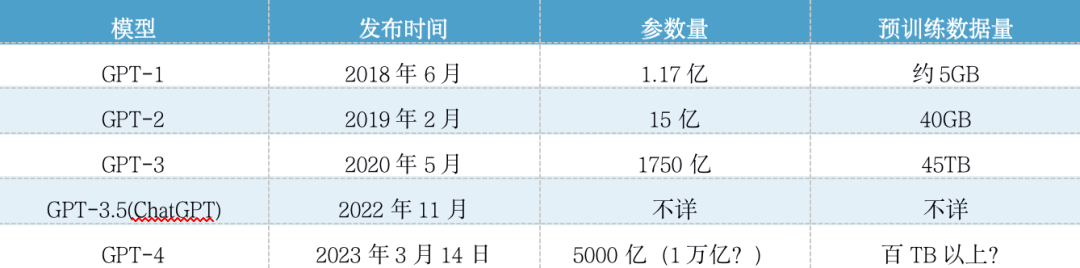
目前,对于想要使用chatGPT retrival plugin的企业来说,必须使用OpenAI的text-embedding-ada-002模型来将数据进行向量化。而text-embedding-ada-002模型,现在只由OpenAI提供的API来在线调用,无法进行私有化部署和本地化部署。
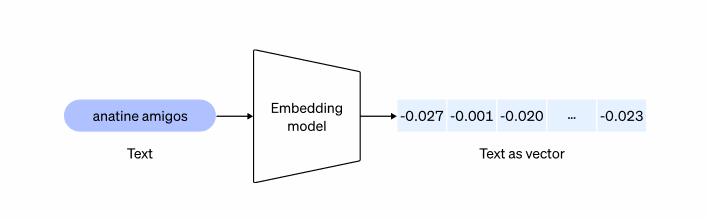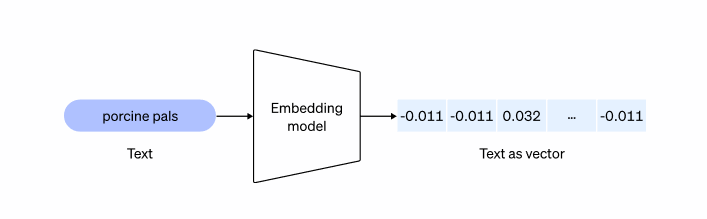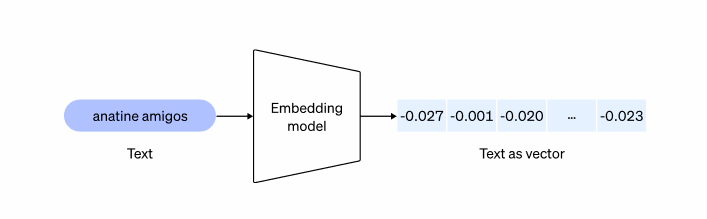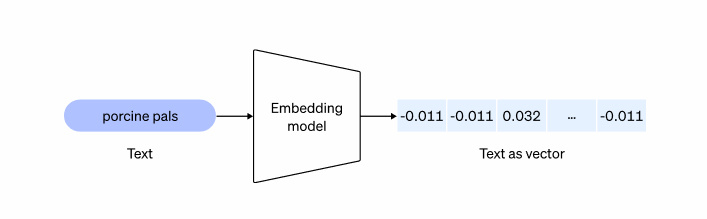
API输出的数据将可以存储在chatGPT retrival plugin所支持的向量数据库当中,首批支持包括:
Pinecone
Weaviate
Zilliz
Milvus
Qdrant
Redis
而在未来,类似于Elasticsearch这样的包含向量搜索能力的、被广泛使用的搜索引擎也会支持text-embedding-ada-002模型生成的向量,以及与chatGPT retrival plugin集成。
而用户的查询也需要text-embedding-ada-002模型转化为相同维度的向量,以进行后续的相似性计算。
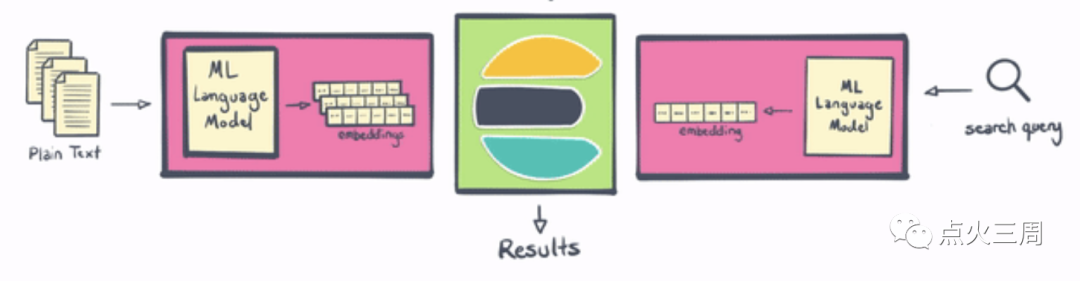
而向量相似性的计算是将上面提到的这些向量库中完成的,而不是在ChatGPT模型中。类似于边缘计算,这种方法的优势在于,向量库通常针对这类任务进行了高度优化,能够在大规模数据集上实现实时查询和高效计算。在这个过程中,ChatGPT模型的主要任务是根据提供的检索到的信息来生成回答,而不是直接参与向量相似性计算。
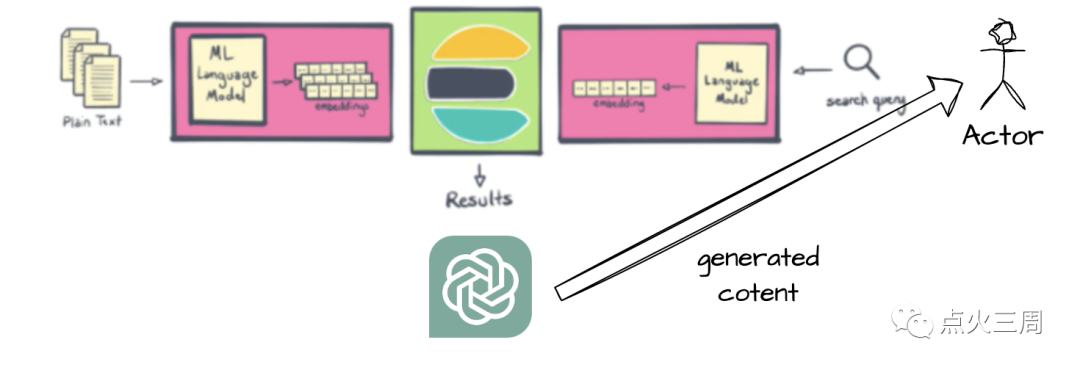
在这个过程中,我们看到,无论是embedding的转换,还是通过chatGPT retrival plugin来给搜索加buff,我们都严重依赖于与OpenAI的集成。每次API的都用都需要给OpenAI付费,对于企业来说将是一笔不小的费用。另一方面,在某些情况下,使用传统的基于分词的全文检索技术仍然是有价值的。虽然基于向量的检索方法在许多场景中具有优势,但它过于昂贵,且并不总是能完全替代基于分词的全文检索技术。在以下场景,我们仍需要使用全文检索技术:
简单查询:对于简单的关键字查询,基于分词的全文检索可能会更快、更直接地找到相关结果。
布尔查询:全文检索技术支持复杂的布尔查询,如AND、OR和NOT操作,以及其他高级查询功能,如近义词查询、模糊查询等。这些功能在基于向量的检索方法中可能难以实现。
精确匹配:基于分词的全文检索技术能够找到精确匹配的文本片段,而基于向量的检索方法可能会在某种程度上损失一些精确性,因为它们主要关注语义相似性。
资源限制:对于资源有限的环境,如硬件限制或预算限制,基于分词的全文检索技术可能相对更易于部署和维护。
因此,在应用生成式搜索的同时,使用基于分词的全文检索技术仍然是有必要的。在实际应用架构中,企业应该根据实际需求和场景来选择合适的检索方法,将基于分词的全文检索技术与基于向量的检索方法结合使用,以获得更好的检索效果。
而升级Elasticsearch的版本,使用能够混合进行全文检索和向量计算的新版本,将是对现有软硬件基础设施最友好的一个方案。(假设现在的搜索业务都是在使用Elasticsearch提供的前提下)
总结
在OpenAI引爆的这一次新的AI工业革命的浪潮之下,我们将看到大量的行业被创新所颠覆。而因为AI过高的门槛,赢家通吃的现象将会比以前更明显。
微软与OpenAI明显的已经领先了很大的身位,他们吃肉,能快速跟进的企业喝汤。后知后觉的企业将被淘汰。
很多行业将出现颠覆与机遇并存的现象,搜索行业正是如此。搜索的新时代已经来临,能用AI赋能的企业将获得更多的生存空间,无法跟上新技术变化的企业将因为过时的体验而失去用户。
闪电发卡ChatGPT产品推荐:
ChatGPT独享账号:https://www.chatgptzh.com/post/86.html
ChatGPT Plus共享账号:https://www.chatgptzh.com/post/319.html
ChatGPT Plus独享账号(购买充值代充订阅):https://www.chatgptzh.com/post/306.html
ChatGPT APIKey购买充值(直连+转发):https://www.chatgptzh.com/post/305.html
ChatGPT Plus国内镜像逆向版:https://www.chatgptzh.com/post/312.html
ChatGPT国内版(AIChat):https://www.chatgptzh.com/post/318.html