在云服务器上搭建个人版ChatGPT及后端Spring Boot集成ChatGPT
一、国内服务器上搭建chat GPT
首先,你需要准备以下东西:
1、一台可以访问公网的Linux云服务器,最低配置1核2G即可(当然,有钱可以任性,买最高配置)
2、ChatGPT的密钥
3、开源的仿ChatGPT的Docker镜像
1.1、准备一台云服务器
可以是腾讯云、阿里云或者华为云等,我分别在阿里云和华为云上都能正常搭建。
1.2、设置网络代理
在部署魔法访问的服务器上,需要在/etc/profile增加代理,确保通过密钥方式的ChatGPT接口调用能正常访问:
export all_proxy=http://127.0.0.1:8889
export http_proxy=http://127.0.0.1:8889
export https_proxy=https://127.0.0.1:8889
export all_proxy=socks5://127.0.0.1:1080
这里的8889和1080需要根据你的魔法访问里的config.json来相应设置。
配置完成后,执行source /etc/profile,检验一下curl https://api.openai.com/
可以访问即没问题。可以继续往下走。
1.3、安装Docker
搭建完成后,因为Docker的对外访问若需要走所在宿主的代理话,还需要设置以下操作——
创建一个~/.docker/目录,然后在该目录下新建一个config.json文件,在该文件里添加以下命令——
{
"default":
{
"httpProxy": "http://127.0.0.1:8889", "httpsProxy": "http://127.0.0.1:8889", "noProxy": "*.test.example.com,.example2.com,127.0.0.0/8"
}
}}1.4、Docker镜像
目前网上GitHub已经开源了许多优秀的仿写chatGPT 页面的应用,我们无需再额外造轮子,只需要挑选其中一款用来打包部署成Docker容器运行即可。
我使用的是chatgpt-mirror这个开源项目。
直接克隆项目到对应的Linux服务器——
git clone https://github.com/yuezk/chatgpt-mirror.git
在基于该开源项目以Dockerfile形式打包前,需要执行以下被依赖到的镜像——
docker pull node:18-alpine docker pull node:18-slim
接下来,就可以执行以下操作来创建一个Docker镜像了——
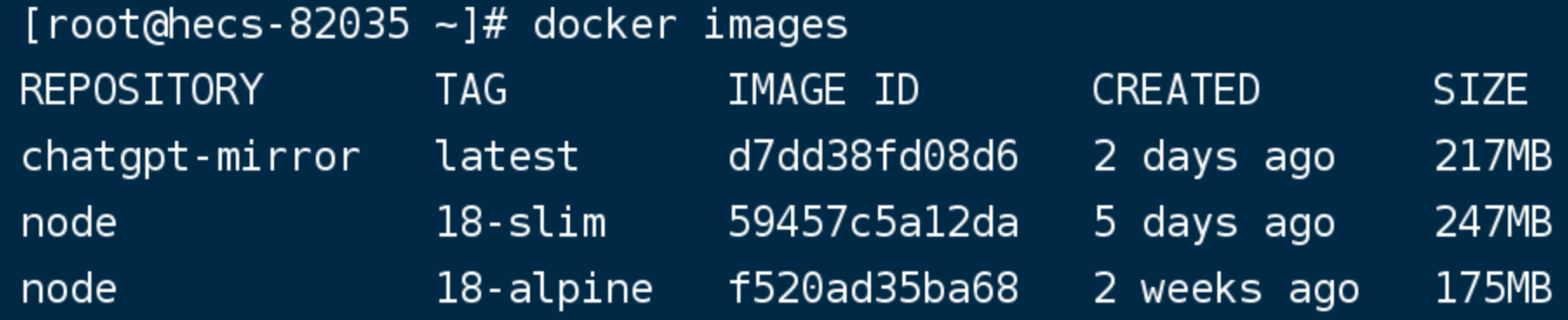
cd chatgpt-mirror#--network host表示与宿主公用网络,即走代理,然后留意下最后有一个 .docker build --network host -t chatgpt-mirror . #正常执行成功后,通过该指令能看到一个新镜像docker images
具体情况如下:
然后需要在cd chatgpt-mirror环境里新增一个文件env,该文件里写入chatGPT密钥与宿主机器的代理:
OPENAI_API_KEY=你的chatGPT密钥 HTTP_PROXY=http://127.0.0.1:8889
完成以上操作后,最后在该目录chatgpt-mirror里执行——
docker run -itd --net host -p 3000:3000 -v /app/config.json:/app/config/app.config --env-file env chatgpt-mirror
正常执行完成后,即可在浏览上输入http://你的服务器ip:3000,就能出来一个外表仿chatGPT但内在是调用真实chatGPT接口的应用。
重点是,如此一来,你的电脑、平台、手机等终端都无需魔法访问,就能直接使用chatGPT了,而且响应速度比直连官网快一倍左右速度,无比丝滑!而且,没有像chatGPT官网直连那样经常出现响应异常以及断开的问题,协助效率大大增加。
以下就是访问搭建在我自己服务器上的chatGPT页面,是不是跟真实的很像。

二、后端Spring Boot集成chat GPT
注意,该方式同样需要魔法访问。
首先,在maven依赖引入以下配置——
<dependency> <groupId>com.theokanning.openai-gpt3-java</groupId> <artifactId>service</artifactId> <version>0.11.1</version></dependency>
编写以下代码——
@GetMapping("/ai")public void sendMsg() throws InterruptedException {
System.out.println("开始提问题~");
System.out.println("你是一个工作助手,情帮忙设计一份活动策划书" );
//GPT_TOKEN即你的代码密钥
OpenAiService service = new OpenAiService(GPT_TOKEN,Duration.ofSeconds(10000));
CompletionRequest completionRequest = CompletionRequest.builder()
//使用的模型
.model("text-davinci-003")
//输入提示语
.prompt("设计一份活动策划书")
//该值越大每次返回的结果越随机,即相似度越小,可选参数,默认值为 1,取值 0-2
.temperature(0.5)
//返回结果最大分词数
.maxTokens(2048)
//与temperature类似
.topP(1D)
.build();
service.createCompletion(completionRequest).getChoices().forEach(System.out::println);
Thread.sleep(6000);}CompletionRequest的属性文档介绍在这里——
https://platform.openai.com/docs/api-reference/completions/create
启动,调用该接口,即可正常使用chat GPT集成到SpringBoot后端代码里——
需要注意的是,若是部署在有魔法访问的Linux云服务,代码需要相应做一下调整,否则是无法访问到chatGPT的,会出现以下异常提示:java.net.ConnectException:Failed to connect to api.openai.com/2a03:2880:f10c:283:face:b00c:0:25de:443]
故而,需要做以下调整:
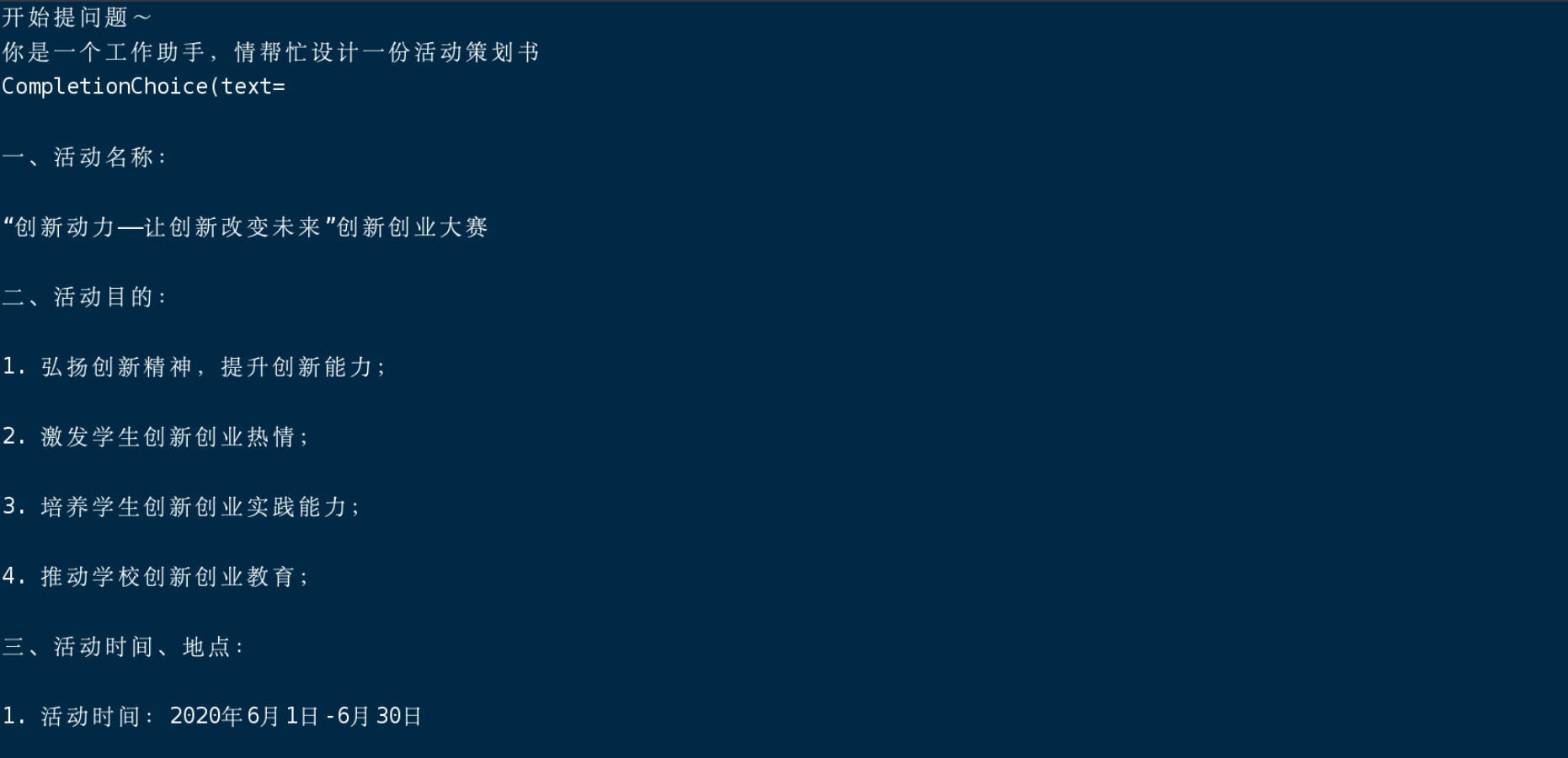
public void send1Msg() throws InterruptedException {
System.out.println("开始提问题~");
System.out.println("你是一个工作助手,情帮忙设计一份活动策划书" );
//需要额外设置一个能访问chatGPT的魔法访问代理
ObjectMapper mapper = defaultObjectMapper();
Proxy proxy = new Proxy(Proxy.Type.HTTP, new InetSocketAddress("127.0.0.1", 8889));
OkHttpClient client = defaultClient(GPT_TOKEN,Duration.ofSeconds(10000))
.newBuilder()
.proxy(proxy)
.build();
Retrofit retrofit = defaultRetrofit(client, mapper);
OpenAiApi api = retrofit.create(OpenAiApi.class);
//将设置的代理传给OpenAiService即可
OpenAiService service = new OpenAiService(api);
CompletionRequest completionRequest = CompletionRequest.builder()
.model("text-davinci-003")
.prompt("设计一份活动策划书")
.temperature(0.5)
.maxTokens(2048)
.topP(1D)
.build();
service.createCompletion(completionRequest).getChoices().forEach(System.out::println);
Thread.sleep(6000);}部署在Linux云服务上的聊天返回打印效果——
以上就是关于【国内服务器上搭建chat GPT】和【后端Spring Boot集成chat GPT】教程,更多好玩的关于chat GPT相关的内容,可以关注我,因为我对这块很感兴趣,接下来会分享更多相关内容。有不懂的也可以后台问我。