ChatGPT API接口编程基础与使用技巧
一、OpenAi Api调用库
OpenAi开放了一系列模型接口API,包括ChatGPT、图像生成、音频、文件、敏感数据拦截等。
若要集成这些模型接口调用到我们开发的系统里,可以通过多种编程语言的HTTP请求与openai API交互。目前OpenAi API支持多种编程语言调用,各类编程语言对应的接口调用库都能在OpenAi官网找到官方推荐的开源库。
我在本文里主要介绍Java、Go、Python、Node.js这四种,其余具体依赖方式和使用,感兴趣的童鞋可自行去官网进一步研究。
1.1、Java
官方推荐的是Theo Kanning开源的openai-java 。我用来集成到SpringBoot项目的依赖库,正好也是用了这款openai-java。
1.1.1、首先,需要在Maven引入以下依赖——
<dependency> <groupId>com.theokanning.openai-gpt3-java</groupId> <artifactId>service</artifactId> <version>0.11.1</version></dependency>
1.1.2、安装完成后,可以参考以下的代码案例,通过绑定密钥来调用chatGPT模型——
@GetMapping("/ai")public void sendMsg() throws InterruptedException {
System.out.println("开始提问题~");
//GPT_TOKEN即你的代码密钥
OpenAiService service = new OpenAiService(GPT_TOKEN,Duration.ofSeconds(10000));
CompletionRequest completionRequest = CompletionRequest.builder()
//使用的模型
.model("text-davinci-003")
//输入提示语
.prompt("你是一个工作助手,请帮忙设计一份活动策划书")
//该值越大每次返回的结果越随机,即相似度越小,可选参数,默认值为 1,取值 0-2
.temperature(0.5)
//返回结果最大分词数
.maxTokens(2048)
//与temperature类似
.topP(1D)
.build();
service.createCompletion(completionRequest).getChoices().forEach(System.out::println);
Thread.sleep(6000);}需要注意的是,若是部署在有"魔法代理"的Linux云服务商,代码需要相应做一下调整,否则是无法访问到ChatGPT的,只会出现以下异常提示:
java.net.ConnectException:Failed to connect to api.openai.com/2a03:2880:f10c:283:face:b00c:0:25de:443]
当日我在这个问题上就踩了一个坑。
解决的办法很简单,只需要做以下调整——
public void send1Msg() throws InterruptedException {
System.out.println("开始提问题~");
//需要额外设置一个能访问chatGPT的魔法访问代理
ObjectMapper mapper = defaultObjectMapper();
Proxy proxy = new Proxy(Proxy.Type.HTTP, new InetSocketAddress("127.0.0.1", 8889));
OkHttpClient client = defaultClient(GPT_TOKEN,Duration.ofSeconds(10000))
.newBuilder()
.proxy(proxy)
.build();
Retrofit retrofit = defaultRetrofit(client, mapper);
OpenAiApi api = retrofit.create(OpenAiApi.class);
//将设置的代理传给OpenAiService即可
OpenAiService service = new OpenAiService(api);
CompletionRequest completionRequest = CompletionRequest.builder()
.model("text-davinci-003")
.prompt("你是一个工作助手,情帮忙设计一份活动策划书,设计一份活动策划书")
.temperature(0.5)
.maxTokens(2048)
.topP(1D)
.build();
service.createCompletion(completionRequest).getChoices().forEach(System.out::println);
Thread.sleep(6000);}1.2、Go
官方推荐的是sashabaranov开源的go-gpt3 。
1.2.1、需要先安装以下依赖包——
go get github.com/sashabaranov/go-openai
1.2.2、该开源项目提供的参考案例如下——
package mainimport (
"context"
"fmt"
openai "github.com/sashabaranov/go-openai")func main() {
client := openai.NewClient("your token")
resp, err := client.CreateChatCompletion(
context.Background(),
openai.ChatCompletionRequest{
Model: openai.GPT3Dot5Turbo,
Messages: []openai.ChatCompletionMessage{
{
Role: openai.ChatMessageRoleUser,
Content: "Hello!",
},
},
},
)
if err != nil {
fmt.Printf("ChatCompletion error: %v\n", err)
return
}
fmt.Println(resp.Choices[0].Message.Content)}1.3、Python
先下载Python版本的open库——
$ pip install openai
安装完成后,可以参考以下的代码案例,通过绑定密钥来调用chatGPT模型——
import osimport openai# Load your API key from an environment variable or secret management serviceopenai.api_key = os.getenv("OPENAI_API_KEY")response = openai.Completion.create(model="text-davinci-003", prompt="Say this is a test", temperature=0, max_tokens=7)1.4、Node
先下载Node版本的openai库——
$ npm install openai
安装完成后,可以参考以下的代码案例,通过绑定密钥来调用chatGPT模型——
const { Configuration, OpenAIApi } = require("openai");const configuration = new Configuration({
apiKey: process.env.OPENAI_API_KEY,});const openai = new OpenAIApi(configuration);const response = await openai.createCompletion({
model: "text-davinci-003",
prompt: "Say this is a test",
temperature: 0,
max_tokens: 7,});二、密钥认证
OpenAi API是需要使用API密钥进行认证访问。密钥获取方式,需要登录https://platform.openai.com/account/api-keys页面。
接着点击【Create new secret key】生成一个新的密钥,需要注意一点是,该密钥生成时就得保存下来,否则过后是无法再进行查看的,例如,我的密钥库里先前已有一条密钥,但现在无法再去确定这条密钥是什么了。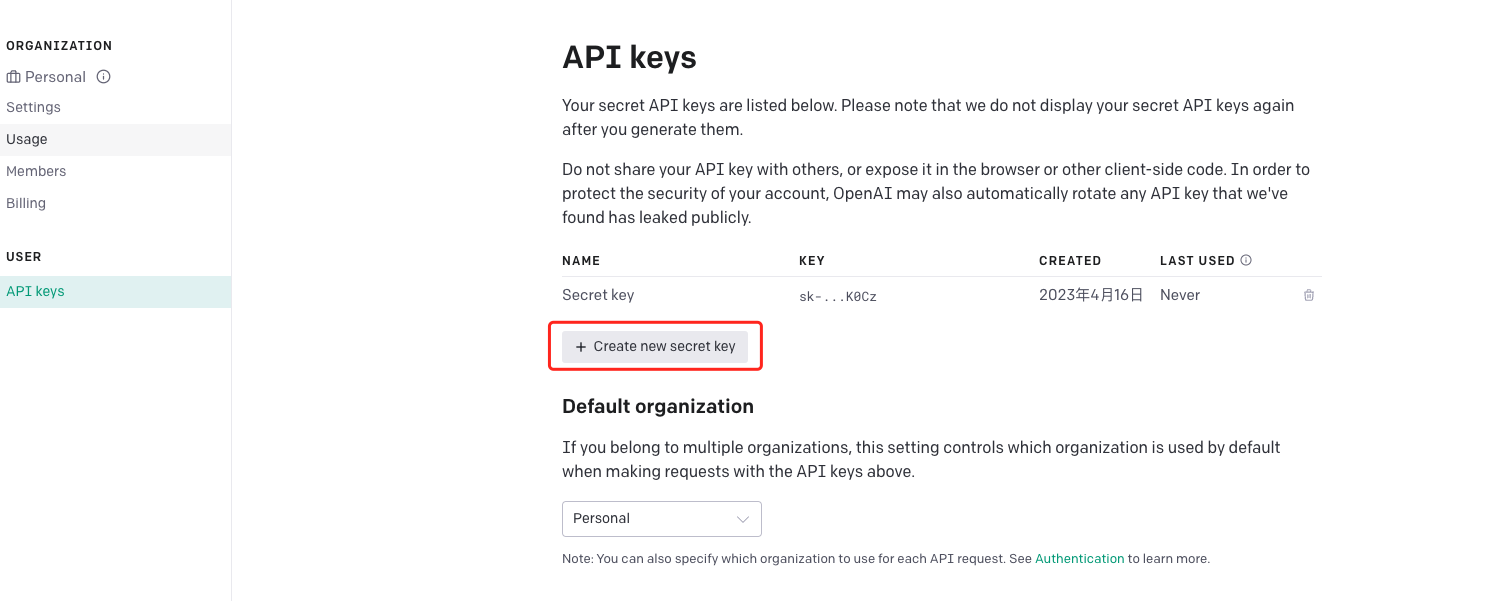
顺便提一点是,chatGPT是有免费额度的,调用API会消耗掉这些额度,我们可以在点击左边菜单【Usage】查看——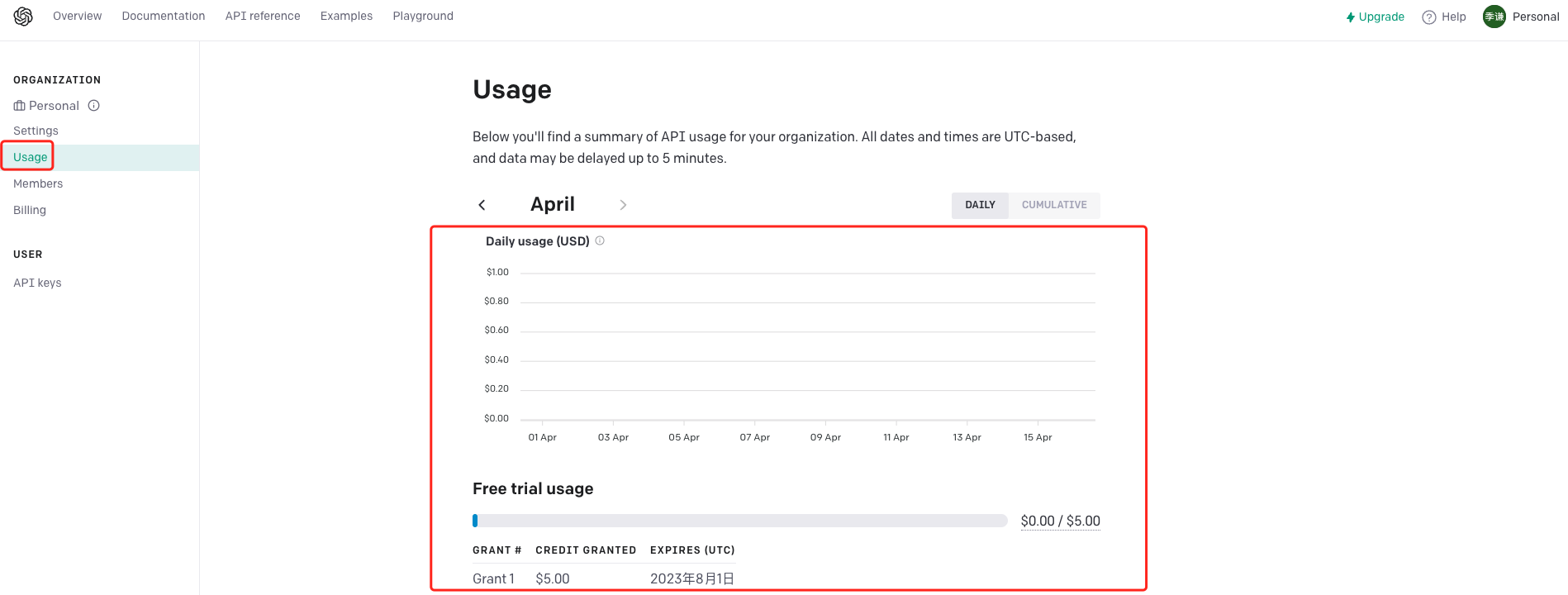
在调用OpenAi的API请求时,需要在HTTP请求报头中包含该API密钥,例如——
Authorization: Bearer OPENAI_API_KEY
三、GPT请求设置
官方提供了一个curl通过密钥调用API的请求案例,需要将案例里的$OPENAI_API_KEY替换为自己的API密钥,在开启了代理的服务器上运行,可以基于该案例测试服务器是否能正常调用到ChatGPT——
curl https://api.openai.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"model": "gpt-3.5-turbo",
"messages": [{"role": "user", "content": "这是一个测试请求!"}],
"temperature": 0.7
}'我在自己的服务器上运行了,返回结果如下——

这个请求表示,查询gpt-3.5-turbo模型完成文本处理,提示语为"这是一个测试请求!",响应结果如下——
{
"id": "chatcmpl-75U8z1PVwDb0pA0EPhOMZVC1q7q11",
"object": "chat.completion",
"created": 1681541869,
"model": "gpt-3.5-turbo",
"usage": {
"prompt_tokens": 14,
"completion_tokens": 46,
"total_tokens": 60
},
"choices": [{
"message": {
"role": "assistant",
"content": "您好,这是一个回复测试请求的信息。请问您有什么需要测试的具体内容或问题吗?我会尽力帮助您解决问题。"
},
"finish_reason": "stop",
"index": 0
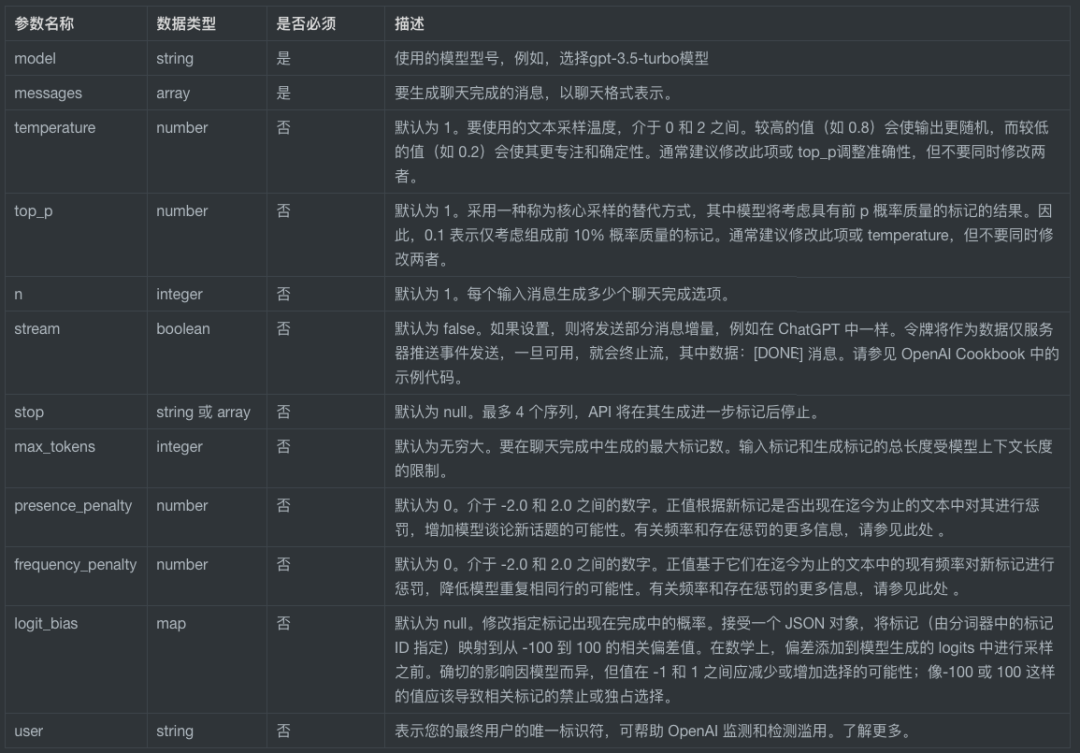
}]}Request body各字段说明——
四、开发中添加敏捷信息审核层
首先得提一下2023年4月11日网信发布的一份《生成式人工智能服务管理办法(征求意见稿)》,里面第四条明确表示,生成式人工智能算法或服务应当遵守法律法规的要求,尊重社会公德、公序良俗。这就意味着,未来在使用这类Ai接口进行输入/输出时,必须针对内容进行违规内容信息的过滤。
其实OpenAi有针对这块内容审核提供了开放的API接口,可以免费使用。
若想在聊天API的输出中添加一个敏捷信息拦截层,就可以在输入/输出信息时,调用该接口。例如,存在这样一份API接口调用案例——
curl https://api.openai.com/v1/moderations \
-X POST \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{"input": "测试一句话"}'响应返回内容如下——
{
"id": "modr-75k0nHCOc0SR88t9xCNBHctPDMO8d",
"model": "text-moderation-004",
"results": [{
"flagged": false,
"categories": {
"sexual": false,
"hate": false,
"violence": false,
"self-harm": false,
"sexual/minors": false,
"hate/threatening": false,
"violence/graphic": false
},
"category_scores": {
"sexual": 0.00012780998076777905,
"hate": 0.00013749735080637038,
"violence": 1.4757171129531343e-07,
"self-harm": 5.410008441231184e-09,
"sexual/minors": 1.5541245375061408e-06,
"hate/threatening": 6.1530336381565576e-09,
"violence/graphic": 2.9580141003293647e-08
}
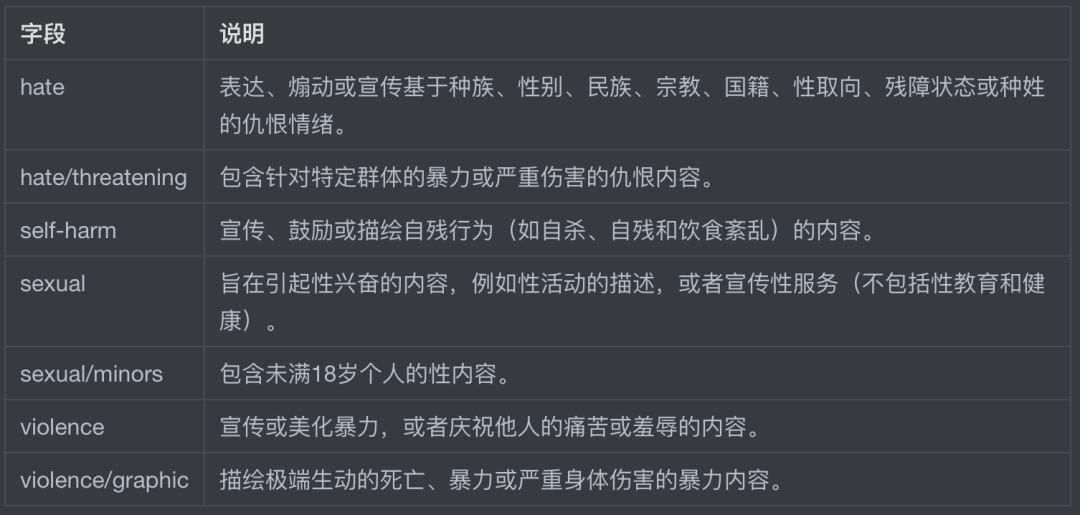
}]}flagged:如果模型将内容属于违反OpenAI的使用策略,则设置为true,否则为false。
categories:包含每个类别二进制使用策略违反标志的字典。对于每个字段值,如果模型将相应类别标记为违规则该值为true,否则为false。
category_scores:包含模型输出的每个类别原始分数的字典,表示模型是否相信输入了违反OpenAI对类别的策略。该值介于0和1之间,其中值越大表示置信度越高。注意一点是,分数不应被解释为概率。
categories和category_scores具体字段值对应的说明如下表格所示——
官方表示目前该审核接口仍在不断努力提高分类器的准确性,特别是仇恨、自残和暴力等内容的分类。值得注意一点是,对非英语语言的支持目前是有限的,也就是说,中文的审核支持比较有限。
除了使用OpenAi提供的输入/输出信息审核接口,还可以开发敏感词过滤系统,将传给ChatGPT以及响应返回的数据,进行敏感词过滤。
四、模型调用
4.1、模型列表
OpenAi提供了多种模型,可以通过执行以下查询指令,查询出API支持的模型类型——
curl https://api.openai.com/v1/models -H "Authorization: Bearer $OPENAI_API_KEY"
出现出来的结果如下,应该有数十个模型,我用的最多是gpt-3.5-turbo,这是目前比较标准的型号版本——
{
"data": [
{
"id": "text-davinci-003",
"object": "model",
"created": 1669599635,
"owned_by": "openai-internal",
"permission": [...],
"root": "text-davinci-003",
"parent": null
},
{
"id": "gpt-3.5-turbo",
"object": "model",
"created": 1677610602,
"owned_by": "openai",
"permission": [...],
"root": "gpt-3.5-turbo",
"parent": null
},
..... ],
"object": "list"}4.2、查询指定 GPT模型详情
可以基于以上模型类表接口,查询出具体模型实例的详情,包括模型的基本信息、所有者及权限等——
curl https://api.openai.com/v1/models/gpt-3.5-turbo \ -H "Authorization: Bearer $OPENAI_API_KEY"
查询出gpt-3.5-turbo的模型详情如下——
{
"id": "gpt-3.5-turbo",
"object": "model",
"created": 1677610602,
"owned_by": "openai",
"permission": [
{
"id": "modelperm-BmdmcAa1aQwToDxri3DFbZw9",
"object": "model_permission",
"created": 1681343255,
"allow_create_engine": false,
"allow_sampling": true,
"allow_logprobs": true,
"allow_search_indices": false,
"allow_view": true,
"allow_fine_tuning": false,
"organization": "*",
"group": null,
"is_blocking": false
}
],
"root": "gpt-3.5-turbo",
"parent": null}GPT-3.5模型可以理解和生成自然语言或代码,在GPT-3.5版本当中,最有能力和最具成本收益的模型是GPT-3.5-turbo,它是基于原有的3.5版本模型进行的迭代优化,可以更好地完成传统任务。目前最新模型是GPT-4,具有更先进的常识和推理能力,但还没有开放免费API接口。
以下是GPT-3.5模型列表介绍——
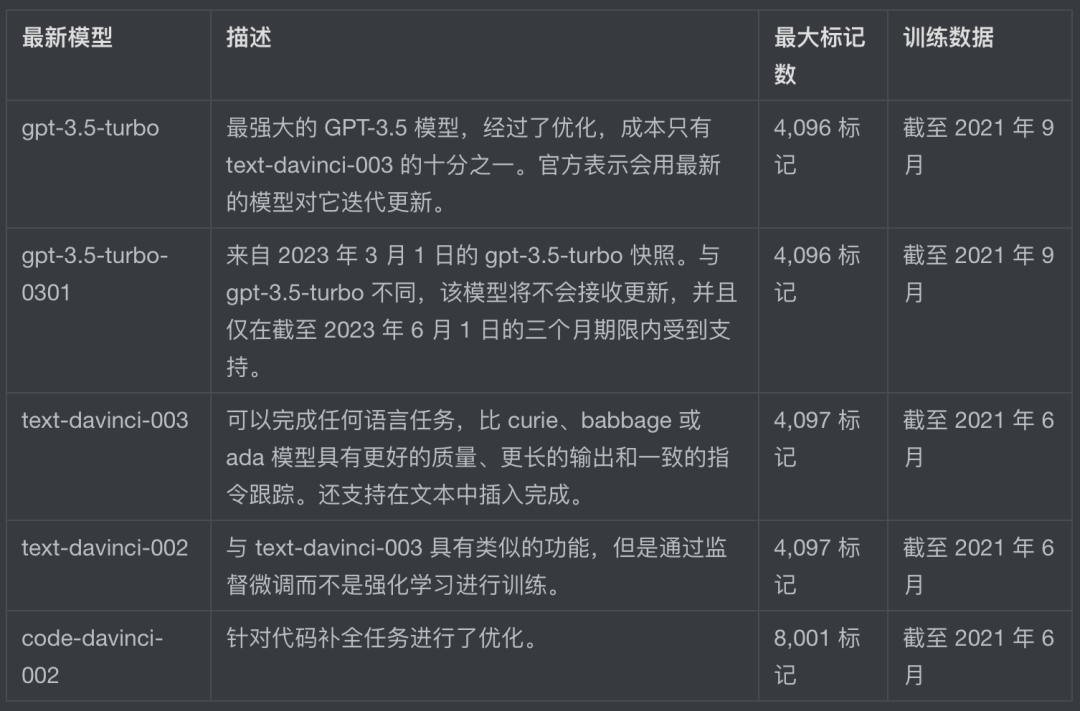
官方推荐使用GPT-3.5-turbo而不是其他GPT-3.5模型,因为它的成本更低。gpt-3.5-turbo的性能与text-davinci-003相似,但每个token的价格是它的10%,官方推荐在大多数情况下使用gpt-3.5-turbo。
五、图像生成调用
给定一个提示和/或一个输入图像,模型会生成一个新的图像,例如,我想让它画一只胖猫——
curl https://api.openai.com/v1/images/generations \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-d '{
"prompt": "画一只可爱的大胖猫",
"n": 2,
"size": "1024x1024"
}'然后,它确实给我画了两张图——
{
"created": 1681547551,
"data": [
{
"url": "https://oaidalleapiprodscus.blob.core.windows.net/private/org-LqdibnOuIlW8xc7Lfh2REsXo/user-6D0yIziBFiX73mCUwNwOwczJ/img-jKdFuRLINlkCeFL1QCWFZtId.png?st=2023-04-15T07%3A32%3A31Z&se=2023-04-15T09%3A32%3A31Z&sp=r&sv=2021-08-06&sr=b&rscd=inline&rsct=image/png&skoid=6aaadede-4fb3-4698-a8f6-684d7786b067&sktid=a48cca56-e6da-484e-a814-9c849652bcb3&skt=2023-04-15T08%3A28%3A22Z&ske=2023-04-16T08%3A28%3A22Z&sks=b&skv=2021-08-06&sig=Rbe8x3ZdEcoScQOXrkxGAe1G8rGOrO%2B4wzmzZwotP68%3D"
},
{
"url": "https://oaidalleapiprodscus.blob.core.windows.net/private/org-LqdibnOuIlW8xc7Lfh2REsXo/user-6D0yIziBFiX73mCUwNwOwczJ/img-00FKmNWnDm5p21CS89UPm56T.png?st=2023-04-15T07%3A32%3A31Z&se=2023-04-15T09%3A32%3A31Z&sp=r&sv=2021-08-06&sr=b&rscd=inline&rsct=image/png&skoid=6aaadede-4fb3-4698-a8f6-684d7786b067&sktid=a48cca56-e6da-484e-a814-9c849652bcb3&skt=2023-04-15T08%3A28%3A22Z&ske=2023-04-16T08%3A28%3A22Z&sks=b&skv=2021-08-06&sig=KVsxjwPIsJFC0cFEjRqVPrcckGxipp5BiiUmayPmqMM%3D"
}
]}通过图url链接,可以查看图片,若是在代码里,可以直接丢给里显示出图片。不过,我让openai给我画的是一只胖猫,图一我还能理解,但是,图二,这个猫屁股着实有些离谱了(自带🐶)......

体验下来,感觉与midjourney还是有较大区别的,只能说,勉强能用吧。
图像生成接口参数如下——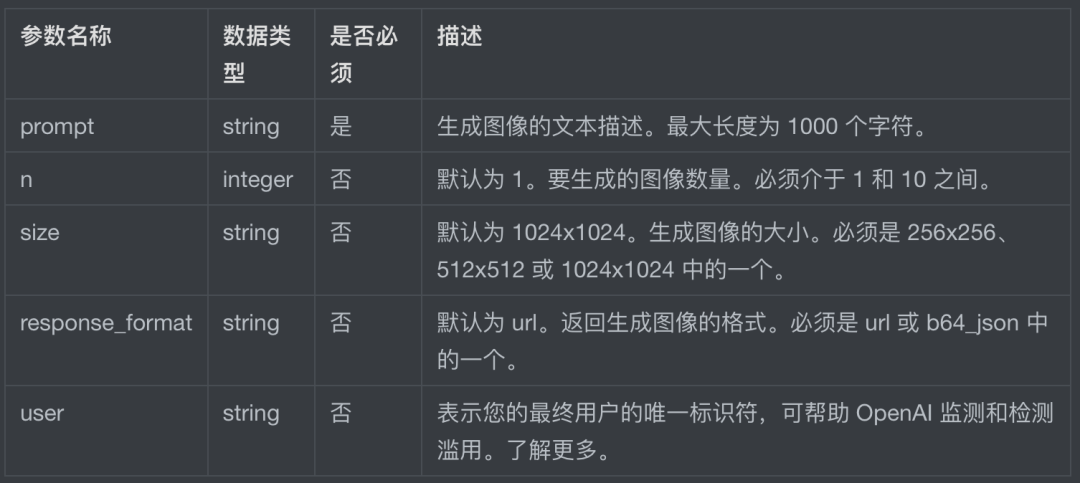
六、ChatGPT使用技巧和注意事项
6.1、调整temperature参数
我在前文调用API的参数当中,有提及一个temperature参数,翻译过来叫温度。该参数用于指定生成文本时的随机性和多样性,默认值为1,介于 0 和 2 之间,较高的温度值值(如 0.8)会导致GPT输出内容更随机,而较低的温度值(如 0.2)会使其更加可以预测和具备确定性。
打一个比喻,ChatGPT中的温度值就演员演戏——
较低的温度值可以看作是“按照剧本表演”,演员是什么水平,就演出什么样子。温度值低生成的文本比较保守和确定,适合需要准确性和连贯性的任务,比如内容摘要、机器翻译等。
较高的温度值可以看成“即兴表演”,生成的文本可能更加随机和多样性,当然,也可能更加糟糕,这种情况比较适合用来创作和探索性任务,比如生成对话、创意写作等。
当然,这个temperature参数并非万能的,在某些文本内容当中,可能几乎感受不到太多差别。
若温度值设置为0,那么,模型将总会返回相同或非常相似的内容,当温度高于0时,每次提交相同的提示会导致生成不同内容。官方表示,温度值在0~1之间,基本上可以控制模型生成比较满意的答案。
例如,当用户询问“如何形容一只胖猫?”时,聊天机器人可能会生成以下不同的回答:
温度值为0.5时:“这是一只肥嘟嘟的猫。”
温度值为1.0时:“这只猫非常胖,它的身体肥厚且圆润,看上去就像一个小球一样。它的肚子很大,当它走路时会晃来晃去,脸上也有一圈又圆又滑的脂肪。总之,这是一只非常非常胖的猫。”
温度值为1.5时:“这只猫的身材简直像是一个小沙发,它的腹部肥厚得几乎抬不起来,四肢也变得特别短。当它走路时,身体会晃动,好像随时都可能翻倒。它的脸宽大而且圆润,双颊上还有一圈厚厚的赘肉,看上去相当可爱。总之,这是一只极其肥胖的猫。”
在提问当中,使用这个参数的方法很简单,只需要在提示语后面跟上“Use a temperature of 0.5”即可——

6.2、传递给API的数据是否会被存储
用户比较关心一个问题是,我们传给ChatGPT的数据是否会被存储。官方表示,自2023年3月1日起,将保留您的API数据30天,但不再使用通过API发送的数据来改进模型。这就意味着,请勿传输涉及个人隐私或者安全相关的信息,避免数据泄漏。


