生成式人工智能的未来会怎样?多模态将把原始的 ChatGPT 演示转向人际协作、先进的机器人技术——甚至可能是持续学习的人工智能梦想

与人工智能的众多重大成就相比——在国际象棋中获胜、预测蛋白质折叠、给猫和狗贴上标签——被称为生成式人工智能的人工智能形式更吸引了全球的想象力。
ChatGPT在 1 月份成为历史上增长最快的软件程序,在公开亮相后不到两个月的时间里就达到了 1 亿用户。它催生了众多竞争对手,既有Google 的 Bard等专有程序,也有加州大学伯克利分校的Koala等开源替代方案。这种兴奋的情绪引发了科技巨头微软和谷歌及其同行之间的军备竞赛,以及人工智能芯片制造商英伟达业务的激增。
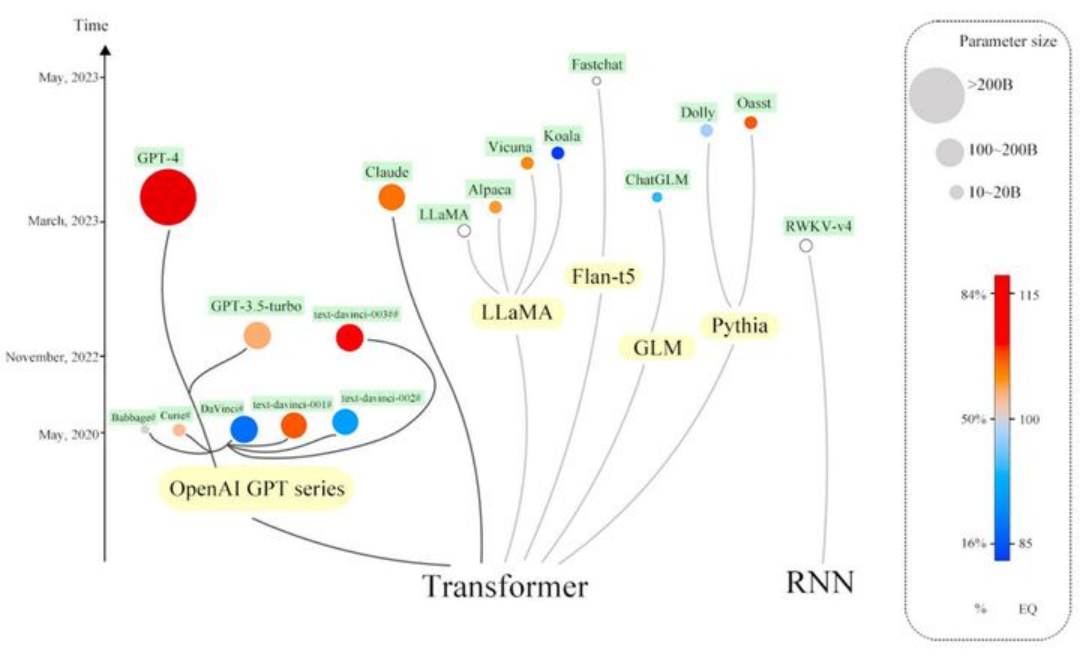
对大型语言模型的兴奋导致了许多专门针对文本的专有和开源程序的兴起,其规模不断扩大。该图来自清华大学王雪娜等人 2023年发表的论文《大型语言模型的情感智能》 。清华大学
所有这些狂热的活动都源于一个简单的事实,即与过去的人工智能程序不同,过去的人工智能程序主要产生数字分数——猫的图片为“1”,狗的图片为“0”——ChatGPT 和图像程序例如Stability AI的Stable Diffusion和OpenAI的DALL-E,再现了世界的某些东西。
通过输出一个段落、一张图片,甚至一个计算机程序的框架,这些程序正在反映社会的创造。
镜像方面将在很短的时间内急剧增加。
与今年年底将流行的程序相比,今天的生成程序显得很原始,因为它们会输出更多种类的东西。
转向多种模式
计算机科学家所说的混合模态或“多模态”将占据中心舞台,因为程序将文本、图像、物理空间的“点云”、声音、视频和整个计算机功能融合为智能应用程序。
混合模式将使能力更强的项目成为可能,并将有助于实现持续学习的长期目标。它甚至可能通过提升机器人技术来推进“嵌入式人工智能”的目标。
AI 初创公司 MosaicML 的创始人 Naveen Rao 在接受 ZDNET 采访时表示:“ChatGPT 是为了娱乐而设计的,它在很多方面都做得非常好,但它在某种程度上只是一个演示。” “现在我们必须开始思考,如果我将其用于某个目的,我该如何让它变得更好?”
Rao 的公司因其在运行人工智能程序方面的专业知识而被 Databricks 收购,现在担任 Databricks 生成人工智能副总裁。
这一改进的一部分将是使生成式人工智能不仅仅是一个个人“副驾驶”,比如微软的 GitHub Copilot,它可以帮助单个人输入聊天提示。Stability AI 创始人兼首席执行官 Emad Mostaque 在接受 ZDNET 采访时表示,这些项目将成为团队的协作项目。
“很多人工智能只是用作一对一的事物,或者它是一个自主代理,”莫斯塔克说。“现在处于 iPhone 2G 阶段,它只是单一模式,你可以剪切和粘贴,而我认为最令人兴奋的事情是我们如何更好地合作并用它讲述更好的故事,而这不是一个单独的努力。”
Databricks 的 Rao 表示,“从根本上缺失的一件事是世界的多模态性”,因为“大型语言模型是非常一维的,因为它们只能通过文本来看待世界。”
模态是指输入和输出的性质,例如文本、图像或视频。多种模式都是可能的,并且已经以越来越多样化的方式进行了探索,因为驱动 ChatGPT 的相同基本概念可以应用于任何类型的输入。
“毫无疑问,多模式是出路,”莫斯塔克说。“你需要各种类型的模型,也许如果你把它们放在一起,那就太棒了。”
著名计算机芯片设计师、人工智能芯片初创公司 Tenstorrent 的首席执行官吉姆·凯勒 (Jim Keller) 表示:“仅语言的东西引起了很大的关注和兴奋,因此媒体关注这一点,但人们正在认真研究其他事情。” ,接受 ZDNET 采访。凯勒将他的公司押注于处理混合模式将成为人工智能未来的重大需求之一的前景。
适用于任何类型数据的机器
在作为 ChatGPT 技术核心的大型语言模型中,文本被转化为一个标记,一种量化的数学表示。然后,机器必须找到整个短语的屏蔽部分或短语的后半部分缺少的内容。正是这种娱乐行为才产生了 ChatGPT 吐出的段落。
同样,就图像而言,广泛使用的扩散过程(由 Stability AI 的稳定扩散版本推广)会用噪声破坏图像,而重新创建原始图像的行为会训练神经网络生成高保真图像。
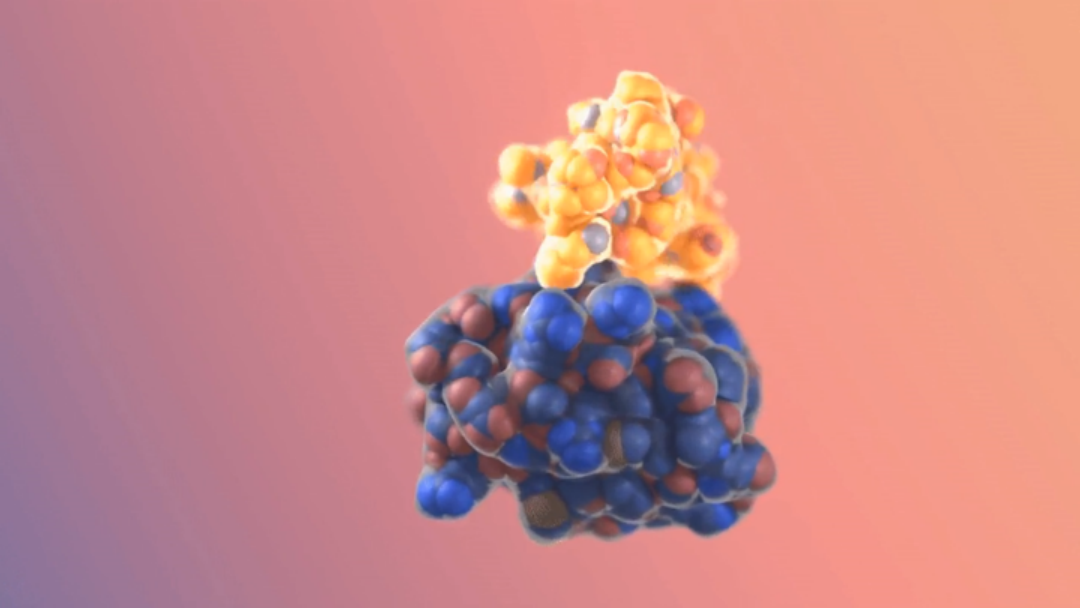
恢复丢失或损坏内容的相同过程正在迅速传播到多种模式或数据类型。例如,在最近一期《自然》杂志中,华盛顿大学生物学家 David Baker 和团队通过他们称为 RF 扩散的过程破坏了蛋白质的氨基酸序列。该过程将训练神经网络在模拟中产生一种具有所需特性的新型合成蛋白质。
这种合成可以大大减少需要发明和测试的蛋白质数量,以产生针对疾病的新型抗体。(《Nature》文章需要付费,但免费版本发布在 bioRxiv 文件服务器上。更多信息可以在Baker Lab 网站上找到。 )
添加图片注释,不超过 140 字(可选)
华盛顿大学蛋白质设计研究所贝克实验室开发的射频扩散过程会破坏氨基酸序列,然后合成一种新的蛋白质结构,就像图像扩散创建图片一样。
华盛顿大学
Stability AI 的 Mostaque 表示:“我们为每种模式都有实验室。”他声称,除了谷歌等科技巨头之外,他的公司和 OpenAI 是“唯一两家独立的多模式公司”。他说,这种多种模式包括 Stability AI 的一个专门用于音频的实验室、一个专门用于代码生成的实验室,甚至还有一个致力于使用稳定扩散技术重新创建 fMRI 图像等工作的生物学实验室。
然而,当更多的方式结合在一起时,奇迹就会发生。莫斯塔克说,这一“突破”是凯瑟琳·克劳森和其他几位研究人员去年的工作成果,他们训练了一个图像生成神经网络,不断完善其输出,直到输出满足基于文本的提示。他们发现,重新处理图像以匹配文本的“语义”内容可以提高图像质量。莫斯塔克指出,克劳森现在在 Stability AI。
许多机构都在迅速开展图文工作。Meta 的人工智能研究人员提出了一种名为CM3Leon的文本和图像机器组合,它不仅擅长输出文本或输出图像,而且还能够同时执行涉及这两种任务的任务,例如识别给定图像中的对象或生成说明文字给定的图像。
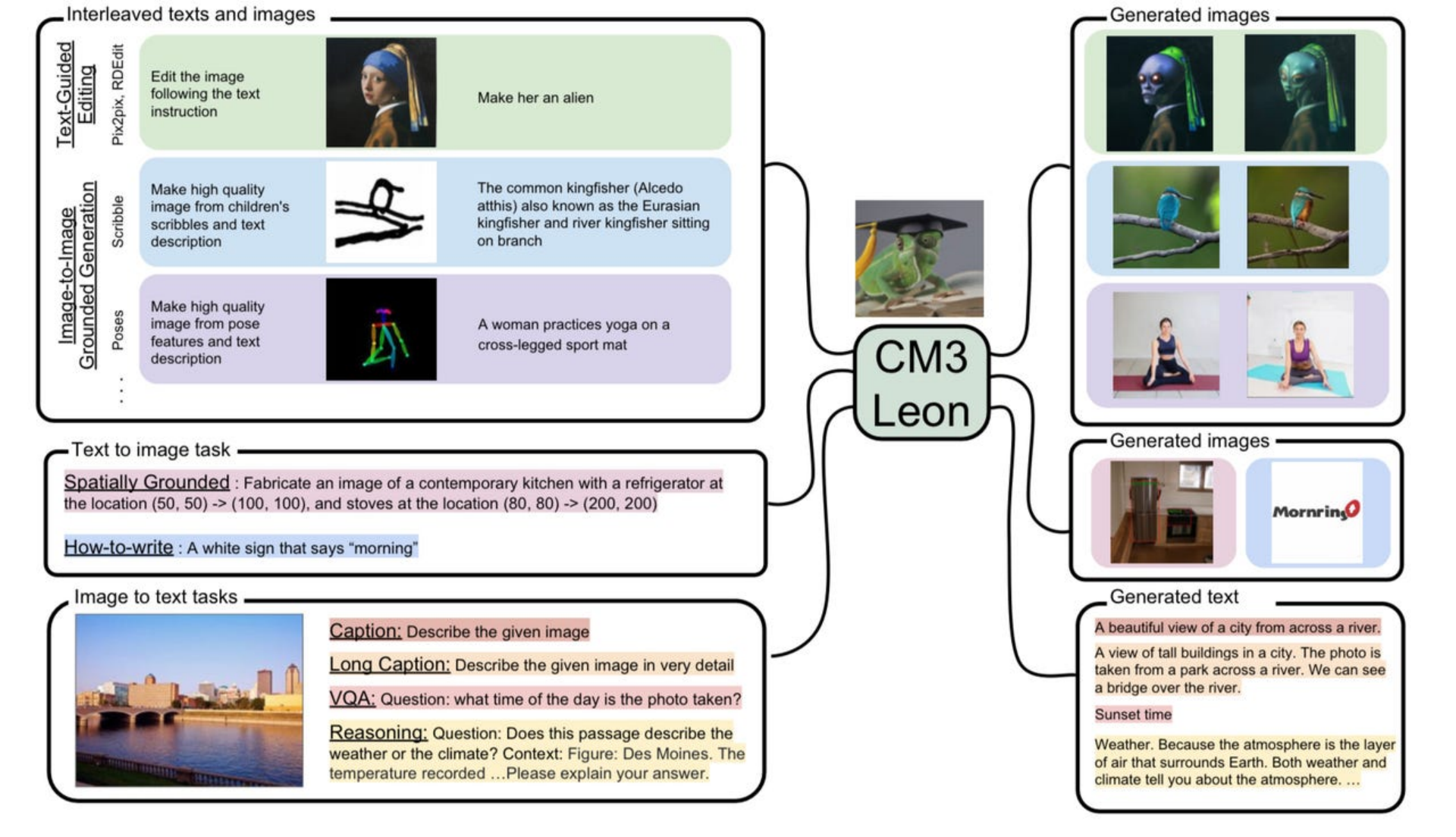
Meta 的 CM3Leon 神经网络混合图像和文本来执行多项任务,例如详细描述给定图像,或精确更改给定图像。 Meta AI 的 Lilu Yu 及其同事 在 2023 年发表的论文《缩放自回归多模态模型:预训练和指令调优》对此进行了详细介绍。
元人工智能
更丰富的世界图景
多种模式的结合开始为神经网络构建更丰富的世界图景。Databricks 的 Rao 引用了“立体视觉”的神经科学概念,这意味着通过触觉来了解世界。如果有人问你口袋里有多少零钱,你可以摸着硬币,不用看就能知道硬币的大小和重量。“我对世界和物体进行了表征,它们实际上以多种方式呈现,”他说。“如果我能学习跨模式的概念,那么我们就做了一些有趣的事情。”
不同的感官充实理解的想法在正在进行的多模态实验中得到了呼应。人们正在积极研究如何制造所谓的“骨干”神经网络,该网络可以混合和匹配一系列令人眼花缭乱的模式,并且它们显示出令人着迷的性能优势。
卡内基梅隆大学的学者 最近提出了他们所谓的“高模态多模态转换器”,它不仅结合了文本、图像、视频和语音,还结合了数据库表信息和时间序列数据。主要作者 Paul Pu Liang 及其同事报告说,他们观察到 10 模式神经网络的“关键缩放行为”。“随着每种模式的增加,性能不断提高,并且转移到全新的模式和任务。”

Paul Liang 及其同事在卡内基梅隆大学 2023 年发表的论文《High-Modality Multimodal Transformer》 不仅结合了文本、图像、视频和语音,还结合了数据库表格信息和时间序列数据。
卡内基·梅隆大学
香港中文大学多媒体实验室的学者张一元及其同事将他们的Meta-Transformer中的模式数量增加到了十几种。其点云模拟 3D 视觉,而其高光谱传感数据代表 从地面 反射回景观飞行图像的电磁能。
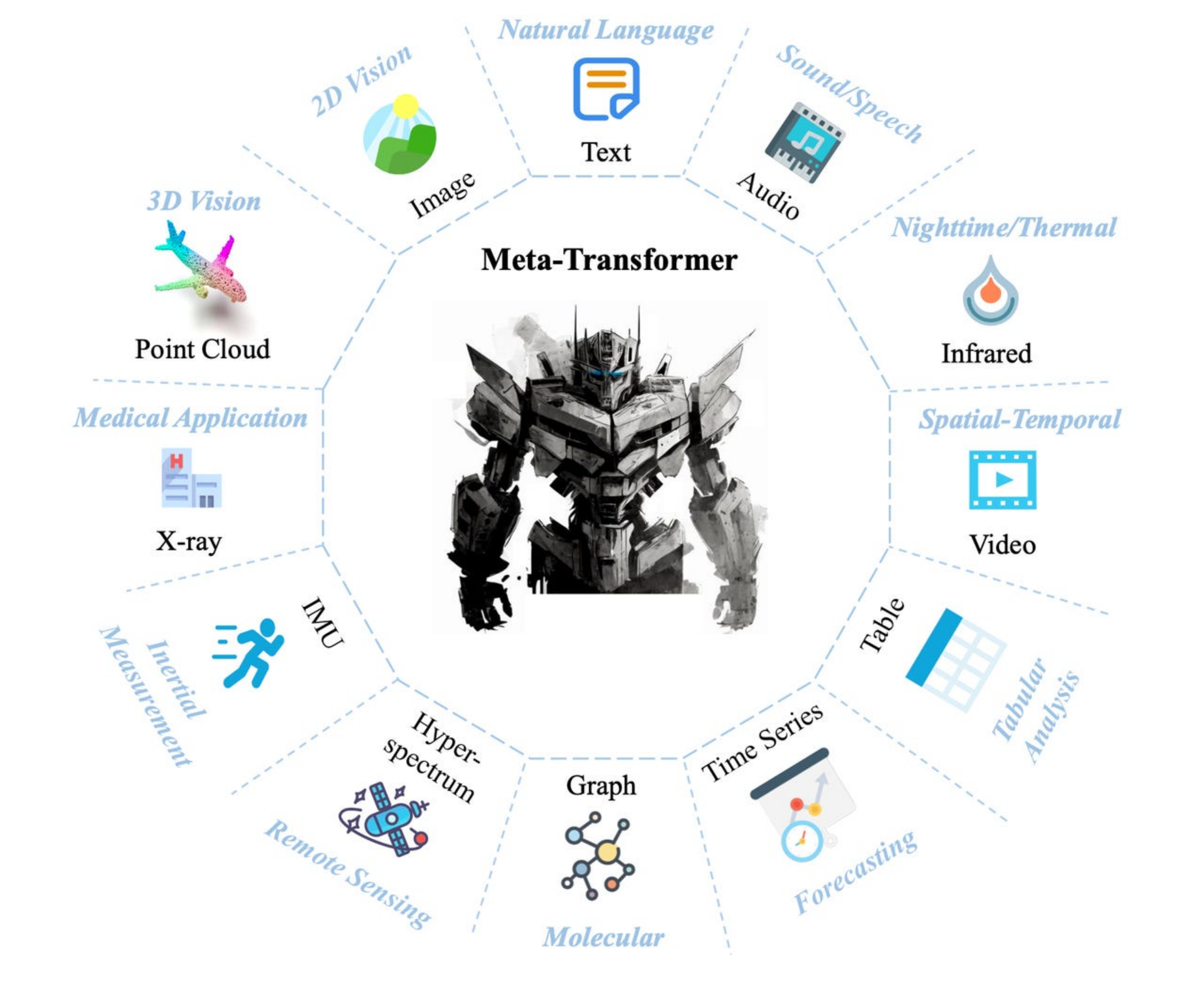
Meta-Transformer 是生成式人工智能的未来,它将大量各种不同类型的数据融合在一起,以更丰富地了解正在产生的输出内容。 香港中文大学多媒体实验室和上海人工智能实验室 OpenGVLab 的张一元及其同事在 2023 年发表的论文 《Meta-Transformer:多模态学习的统一框架》中对此进行了探讨。
香港中文大学/上海人工智能实验室
通过多种模式制作故事书
多模态的直接回报只是以远远超出“演示”模式的方式丰富 ChatGPT 等产品的输出。儿童故事书就是一个直接的例子,一本包含文字段落和说明文字的图片的书。通过结合语言和图像属性,可以更微妙地控制扩散过程创建的图片种类。
正如谷歌科学家和新西兰惠灵顿维多利亚大学首席作者 Wan-Duo Kurt Ma 所解释的那样,一种称为定向扩散的过程可以让猫、城堡或鸟移动穿过不同的场景,从而创造出一种一系列图像不仅提供了更大的控制力,而且还提供了叙事中的过渡。

一种称为定向扩散的技术可以移动一个实体——一只猫、一座城堡、一只鸟——穿过不同的场景,创造出一系列图像,这些图像不仅提供了更大的控制,而且还提供了叙事中的过渡。惠灵顿维多利亚大学和谷歌研究院的 Wan-Duo Kurt Ma 及其同事在 2023 年发表的论文《定向扩散:通过注意力引导直接控制物体放置》对此进行了详细介绍。
同样,韩国成均馆大学的 Hyeonho Jeong 与韩国科学技术院的学者们一起提出了关于扩散的另一个转折点——潜在扩散——他们在最近的一篇论文中详细介绍了这一点。他们声称它可以以低粒度访问图像中的更多细节。
结果是能够生成故事书,其中角色逐个图像地穿过不同的场景,就像在文本提示中添加旋钮以在不同的场景中拨号一样。图像之间对象的一致性就是他们所说的“迭代一致身份注入”。

一种称为潜在扩散的技术通过其发明者所谓的“身份注入”扩展了图像制作,以便通过故事书图像来编写角色的动作。
成均馆大学
正如贝克实验室的蛋白质合成一样,混合模式的应用可能变得非常广泛。剑桥大学工程系的 Chenyu Tang 及其同事最近发表的另一篇论文提出构建“数字孪生”,即通过组合数据对人体进行计算机模拟,绘制所有器官和组织,并描绘血液流动等 来自多个医疗器械在同一过程中稳定扩散。
“运动传感器(例如加速度计、肌电图传感器等)和生化传感器(用于检测疾病相应的生物标志物,例如唾液传感器、汗液传感器等)都可以为患者产生特定的输出,”作者写道。“尽管这些输出具有不同的模式,但它们都对应于同一种疾病。”
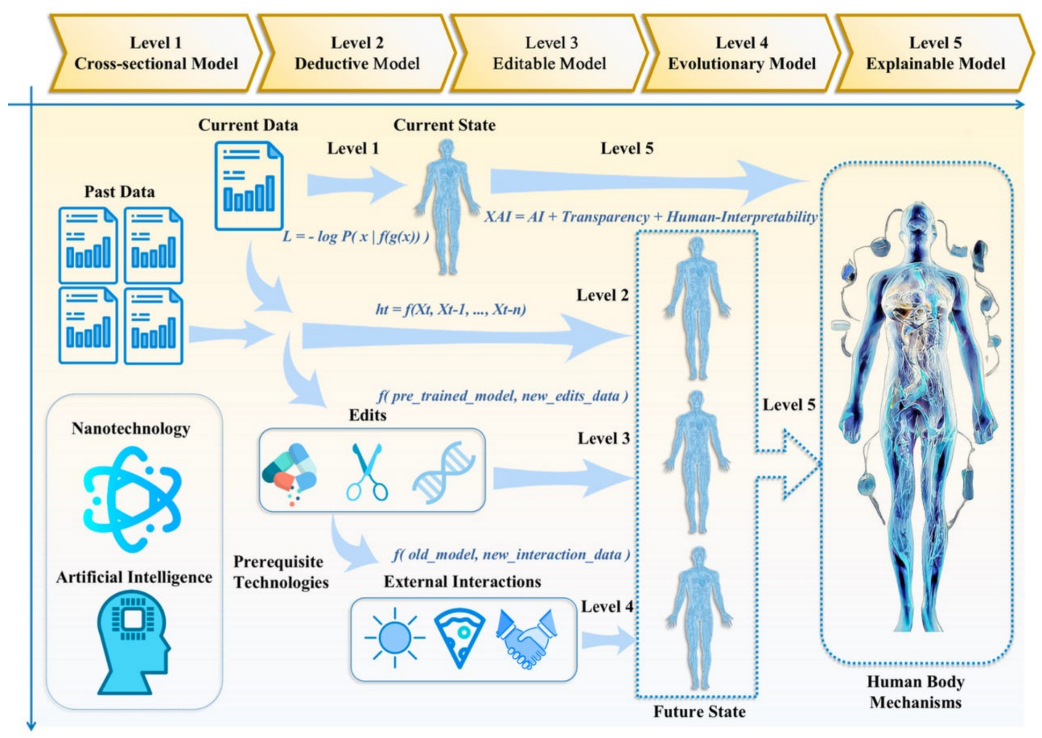
人体的“数字双胞胎”可以通过在稳定扩散的同一过程中组合来自多个医疗仪器的数据来实现。该图代表了“身体 DT [数字孪生] 的五级路线图”,如 剑桥大学 Chenyu Tang 及其同事在 2023 年发表的论文《人体数字孪生:总体规划》中所示。
剑桥大学
特殊模态大师
Stability AI 的 Mostaque 表示,如何组合这些模式与选择哪些模式同样重要。“最后一点将是组合,因为我们构建的这些构建块被放入人工智能优先的适当软件中,该软件使用这些很酷的新工具重新构想所有这些创造、消费和这些流程,”他说。
他说,虽然可能会调用一些大型模型,例如 Google 的 PaLM LLM 或 GPT-4,但许多混合模式将作为组件的编排而发生。“如何以真正有趣的方式将模型组合在一起,并使许多不同的模型协同工作以实现您想要真正增强的结果?”
他说,虽然 PaLM 和 GPT-4 可能很强大,但有充分的证据表明“更多专业模型可以胜过”最大的程序。因此,“我认为,我们将拥有很多跨模式的专业模型,”他说,这是一个将技术“解构”为其适当角色的过程,“然后是一些多模式模型他们可以做任何事情,并且他们会在适当的时间被召唤去做适当的事情。”
机器人技术是下一个人工智能前沿
对于机器人技术形式的实体人工智能领域来说,模式的混合值得注意。
加州大学伯克利分校电气工程系副教授谢尔盖·莱文 (Sergey Levine) 告诉 ZDNET,由于它与生成式人工智能相关,因此机器人系统发挥着重要作用。
“多模式的东西非常令人兴奋,”莱文补充道,他是伯克利大学人工智能研究机构的成员,也与谷歌的团队合作。
他说,通过处理图像和文本,多模式神经网络已经能够产生“高级机器人命令”。莱文说,机器人专家通常编写的用来指导机器人的代码可以“本质上是完全自动化的”。
“我们想要的是能够快速、轻松地命令机器人做事,”莱文说。“语言模型最擅长弥合这一差距。”
Levine 帮助监督了最近在 Google 发布的一个早期演示,名为 PaLM-E,Google 研究人员将其称为“一种体现的多模态语言模型”。机器人能够遵循一系列指令,例如“从抽屉里给我拿米片”,语言模型将其分解为原子指令,例如“去抽屉”、“打开抽屉”、“拿起绿色米片袋”等
谷歌 DeepMind 部门的后续工作称为 RT-2,在 PaLM-E 的基础上增加了为机器人生成空间坐标的能力。莱文称这项工作是“一项重大进步”。
与立体认知的概念一样,莱文认为,增加模式可能会带来丰富的世界模型,从而带来一些基本的推理能力。
Levine 说,如果大型语言模型和扩散模型能够整合“获取先前图像并预测[文本]描述,并获取先前描述并预测图像”的过程,“现在它们可能会开始,在某种程度上,进一步深入研究术语”。他们如何理解世界。”
世界知识的一个原始例子是 Levine 开发的机器人调酒师,它会检查人们的 ID “你实际上可以告诉语言模型,为我写一些机器人调酒师的代码,它会生成一些逻辑来做到这一点,如果有人点一杯水,这不是酒精饮料,”因此不需要检查身份。
我们将需要更多的内存
机器人技术和多模态的结合具有更深远的影响,因为它极大地扩大了对数据的需求。如今的生成式人工智能(例如 ChatGPT)没有显式记忆。它只适用于您在提示符下输入的最后一堆内容,过了一段时间,它就会忘记很久以前的事情。
使用包含更多数据样本的混合模式将迫使生成式人工智能开发出类似于真实数据记忆的东西。Levine 说:“当我们开始转向多模态模型时,对上下文的要求开始变得更高,因为该模型的当前原型接受一张图像,但也许你想给它一千张图像。
“也许你想让它参观一下你的房子,这样它就知道你房子里的所有东西都在哪里,这样当你要求它给你拿车钥匙时,它就可以检查它的记忆并找出车钥匙的位置是——现在这需要更长的背景。”
视频数据对于让机器人构建世界肖像来说同样重要,甚至更重要。莱文说,这些视频与文本、点云和其他模式相结合,成为一个模拟器,机器人可以通过它构建世界模型。“如果这些模型本质上提供了一种学习非常高保真度模拟器的方法,那么这可能会对未来产生非常重大的影响。”
扩展到数千张图像和可能数小时的视频,也许是千兆字节的点云、3D 数据来训练多模式程序,这意味着 ChatGPT 和其他公司将必须通过所谓的内存库大幅扩展对数据的访问。
人们正在努力通过所谓的数据库检索来“增强”语言模型。这可以在 Meta 的 CM3Leon 程序中看到,该程序可以让软件深入数据库并查找相关图像。
斯坦福大学和加拿大 MILA 研究所的鬣狗技术等努力试图显着扩展程序提示的内容,以便可以输入任何数量、任何形式的数据。
这意味着除了混合模式之外,ChatGPT 的后继者将能够处理更大的背景——整本书、一系列文章、电影和三维物理结构的记录。这也意味着任何任务的背景都可以变得更加适合个人或团体所获得的知识。Mostaque 表示,这样的模型不仅会带来 GPT-4 的广义知识,还会带来具体知识,以及您的团队、公司和其他方面的知识。
莫斯塔克表示:“我认为,当明年它进入企业时,这是一个重大的解锁。”他指的是生成式人工智能即将在企业环境中广泛采用。

