ChatGPT 能预测未来吗?训练人工智能弄清楚接下来会发生什么
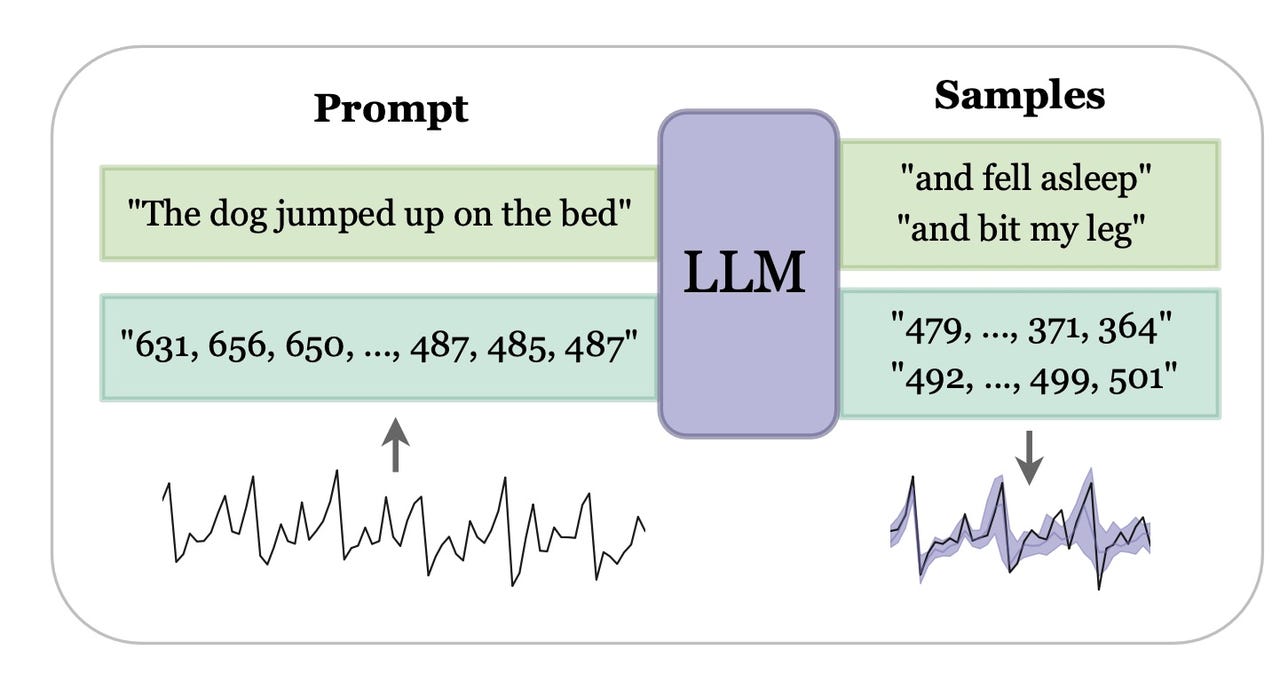
纽约大学的 LLMtime 程序在一系列事件中查找下一个可能的事件,如数字字符串所示。
正如 ZDNET 所深入探索的那样,今天的生成式人工智能程序、ChatGPT 等工具将产生比文本更多种类的结果。
众所周知,这些“模式”中最重要的一种是所谓的时间序列数据,即在不同时间点测量相同变量以发现趋势的数据。时间序列格式的数据对于诸如通过医生在图表中输入的条目跟踪一段时间内的患者病史等事情非常重要。进行所谓的时间序列预测意味着获取历史数据并预测接下来会发生什么;例如:“这个病人会好起来吗?”
时间序列数据的传统方法涉及专门为该类型数据设计的软件。但现在,生成式人工智能正在获得一种新的能力来处理时间序列数据,就像处理问答题、图像生成、软件编码以及 ChatGPT 和类似程序擅长的其他各种任务一样。
在纽约大学的 Nate Gruver 以及纽约大学和卡内基梅隆大学的同事本月发表的一项新研究中,OpenAI 的 GPT-3 程序经过训练,可以预测时间序列中的下一个事件,类似于预测句子中的下一个单词。
“因为语言模型是为了表示序列上的复杂概率分布而构建的,所以理论上它们非常适合时间序列建模,”Gruver 和团队在他们的论文“大型语言模型是零样本时间序列预测器”中写道,该论文发表在arXiv 预印本服务器。“时间序列数据通常采用与语言建模数据完全相同的形式,即序列的集合。”
Gruver 和团队写道,他们创建的程序 LLMTime“非常简单”,并且能够“以零样本的方式在一系列不同问题上超越或匹配专门构建的时间序列方法,这意味着可以使用LLMTime无需对其他模型使用的下游数据进行任何微调。”
构建 LLMTime 的关键是 Gruver 和团队重新思考所谓的“标记化”,即大型语言模型表示其正在处理的数据的方式。
GPT-3 等程序有一种特定的输入单词和字符的方式,将它们分解成可以一次提取一个的块。时间序列数据表示为数字序列,例如“123”;时间序列就是此类数字序列发生的模式。
鉴于此,GPT-3 的标记化是有问题的,因为它通常会将这些字符串分解成尴尬的分组。“例如,数字 42235630 被 GPT-3 标记器标记为 [422,35,630],即使是一位数字的变化也可能导致完全不同的标记化,”Gruver 和团队表示。
为了避免这些尴尬的分组,格鲁弗和团队构建了代码,在数字序列的每个数字周围插入空格,以便每个数字都被单独编码。
然后,他们开始训练 GPT-3,以预测现实世界时间序列示例中的下一个数字序列。
任何时间序列都是一系列相继发生的事件,例如“狗从沙发上跳下来,跑到门口”,其中有一个事件,然后是另一个事件。人们想要进行预测的真实数据集的一个例子是根据历史提款预测 ATM 提款。银行会对预测此类事情非常感兴趣。
事实上,ATM 取款预测是实时系列竞赛的挑战之一,例如英国兰卡斯特大学举办的人工神经网络和计算智能预测竞赛。该数据集只是字符串和数字字符串,其形式如下:
T1:1996-03-18 00-00-00:13.4070294784581、14.7250566893424等
第一部分显然是“T1”的日期和时间戳,代表时间的第一个时刻,接下来是金额(用点分隔,而不是欧洲表示法中的逗号分隔)。神经网络面临的挑战是,在给定数千甚至数百万个此类项目的情况下,预测在本系列最后一个示例之后的下一个时刻会发生什么——明天客户将提取多少金额。
作者表示,“LLMTime 不仅能够生成真实和合成时间序列的合理完成,而且在零样本评估中,它比已经创建了数十年的专用时间序列模型 [...] 实现了更高的可能性 [...]” 。

LLMtime 程序查找数字在分布中的位置,即数字重复出现的独特模式,以得出序列是否代表常见模式之一(例如“指数”或高斯)。
然而,格鲁弗和团队指出,大型语言模型的局限性之一是它们一次只能接受这么多数据,称为“上下文窗口”。为了处理越来越大的时间序列,程序需要将上下文窗口扩展到更多的标记。这是一个由斯坦福大学Hyena 团队、加拿大MILA 人工智能研究所和微软等多方共同探索的项目。
显而易见的问题是为什么大型语言模型应该擅长预测数字。正如作者指出的,对于任何数字序列(例如 ATM 提款),都存在“任意多个与输入一致的生成规则”。翻译:出现这些特定数字串的原因有很多,很难猜测解释它们的基本规则是什么。
答案是 GPT-3 及其同类找到所有可能规则中最简单的规则。“法学硕士可以有效地进行预测,因为他们更喜欢从简单规则中得出的结果,采用奥卡姆剃刀的形式,”格鲁弗和团队在提到简约原则时写道。

有时,当 GPT-4 程序试图推理出时间序列的模式是什么时,它会误入歧途,表明它实际上并没有“理解”传统意义上的时间序列。
这并不意味着 GPT-3 真正了解 正在发生的事情。在第二个实验中,Gruver 和团队向 GPT-4(GPT-3 更强大的后继者)提交了他们使用特定数学函数组成的新数据集。他们要求 GPT-4 推导产生时间序列的数学函数,以回答“GPT-4 是否可以用文本解释其对给定时间序列的理解”的问题,Gruver 和团队写道。
他们发现 GPT-4 能够比随机概率更好地猜测数学函数,但它产生了一些不切实际的解释。“该模型有时会对它所看到的数据的行为或候选函数的预期行为做出错误的推论。” 换句话说,即使像 GPT-4 这样的程序能够很好地预测时间序列中的下一件事,它的解释最终还是“幻觉”,即提供错误答案的倾向。
Gruver 和团队对时间序列如何适应生成人工智能的多模式未来充满热情。他们在结论部分写道:“将时间序列预测构建为自然语言生成可以被视为在单个大型且强大的模型中统一更多功能的又一步,其中可以在许多任务和模式之间共享理解。”